
During a weekend hackathon with some of the Lincoln Lab maintainers of PANDA, I implemented a really useful feature — time-travel debugging!
As has been discussed in Ret2Systems’ great blog post, time-travel debugging is an invaluable tool in the reverse engineer’s arsenal. While Mozilla’s brilliant rr is the dominant choice for Linux user binaries and WinDBG Preview works on Windows binaries, PANDA can debug user and kernel space on both systems.
In this blog post, I’ll talk about the simple design behind reverse-execution and demonstrate its utility in root-causing a Linux kernel n-day.
Design
PANDA, which is built on the QEMU emulator, has the ability to record-replay a full system running a variety of architectures. Non-deterministic events such as hardware interrupts, timestamp reads, etc. are recorded in a logfile and read back during replay, synchronized by the guest instruction index. This allows you to capture and analyze a recording of a whole system, but until now, only in the forward direction.
QEMU also contains a GDB stub that can talk to a remote GDB client. We extended this debug mechanism to enable reverse execution, as well as other useful debugging commands inspired by Mozilla rr.
Reverse execution
We implemented the two commands reverse-step and reverse-continue in the simplest possible way given existing mechanisms.
To be able to time-travel, we wrote a checkpointing API built on QEMU’s savevm. Checkpoints are just snapshots of all guest state. When checkpointing is enabled, checkpoints are periodically taken, depending on how much space you make available on RAM or disk to store them.
When reverse-step is invoked, PANDA sets a breakpoint on the previous guest instruction count, restores to the latest checkpoint and runs forward until that breakpoint is hit.
reverse-continue is a little more complex. It requires at least two restores to reach the next breakpoint — on the first run forward, PANDA doesn’t break on any breakpoints, but records the last breakpoint encountered. Then, it restores to that checkpoint again and runs until that last breakpoint.
Here’s this case, represented pictorially:

However, if no breakpoints were encountered, PANDA will restore to the previous checkpoint and do the same procedure, until it either finds a breakpoint to halt on, or reaches the beginning of the replay.
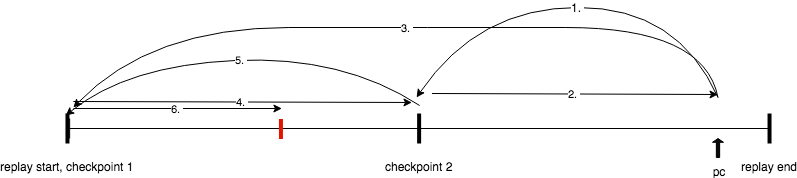
This means that you can use watchpoints and breakpoints just like normal under reverse! We also added several GDB utility commands, including when to get the current guest instruction count and rrbreakpoint to set a breakpoint on a guest instruction count. You can peruse the full list here.
Using time-travel to root cause a Linux kernel n-day
To demonstrate an exciting use of PANDA time-travel, I figured it would be hip and cool to show off this capability with a Linux kernel root-cause-analysis.
CVE-2014-3153
CVE-2014-3153 was famously used in geohot’s towelroot exploit to jailbreak the Samsung Galaxy S5. Broadly, it involves a bug in Linux’s fast userspace mutexes, or futexes — a certain sequence of a few interleaved futex syscalls will cause memory corruption. futexes are basically locks which can have a list of waiters with different priority levels. Each futex is associated with a userspace int uaddr, which stores the thread id of the thread, if any, that holds the lock. See references for more background info, but it’s not necessary for this post.
Using a PoC borrowed from this fantastic writeup, I’ll show how to record it under PANDA and use reverse-debugging to identify the vulnerability. Here’s the simplified PoC, with operations ordered by number (you’d have to enforce the order using thread locks).
1 | int uaddrA = 0, uaddrB = 0; |
The futex_wait_requeue_pi man page basically says that the caller will acquire uaddrA and wait for uaddrB to be released. futex_requeue will take care of either adding the waiting thread to uaddrB's wait list or waking it up.
Making a recording
First, let’s make a PANDA recording of the PoC and the resulting crash. I’m using an x86 qcow which has the Linux kernel 3.2.51.
As you can see, we got an invalid opcode kernel panic in rt_mutex_top_waiter, which grabs the waiter at the head of a futex’s wait list. rt_mutexes are just another type of lock that’s used to help implement futexes. We can use time-travel on the replay to work out how this happened.
Loading kernel symbols and isolating the panic
To start the replay and wait for a GDB attach, we just need to do {path_to_qemu}/qemu-system-i386 {path_to_qcow}/wheezy_panda2.qcow2 -replay towelroot_poc -S -s -panda checkpoint
Next, connect GDB with gdb -x ~/panda/panda/scripts/gdbinit -ex 'target remote localhost:1234'. To get kernel source and debug symbols, you can download from this mirror and this link, then run these commands:
1 | dir /home/raywang/linux-3.2.51 |
If you have symbols for a user binary, you can add more symbol files if you specify the load address, like add-symbol-file towelroot_poc 0x080486c0.
Let’s begin by setting a breakpoint on rt_mutex_top_waiter(). We can see exactly where the illegal ud2 op is generated, resulting in the panic we saw above.
So, the offending line is
1 | => rtmutex_common.h:72 |
So why does the sanity check w->lock != lock fail? If we print the rt_mutex_waiter object w, we can clearly see that it’s corrupted.
1 | 74 BUG_ON(w->lock != lock); |
Notice the nonsensical priority list fields, such as the int priority prio = 0xc5230000 and list pointer next = 0x8, as well as the incorrect lock value.
Let’s set a watchpoint on this rt_waiter to see where it came from and how it’s modified. We also set breakpoints on the futex syscalls, futex_requeue() and futex_wait_requeue_pi().
Returning to source
Going back, we can see that several unrelated kernel functions, like apic_timer_interrupt, __do_fault, etc. are overwriting the rt_waiter, which seems like a dangling object.
But if we rc a few more times, we can return to the first call to futex_requeue, which actually iterates over all queued waiters and adds them to uaddrB's wait_list, via rt_mutex_start_proxy_lock and task_blocks_on_mutex. But where is waiter initialized? We can rewind even further, using a watchpoint on the entire waiter object, to see where it is declared.
Aha! We’ve found the origin of the waiter! It’s allocated on the stack of futex_wait_requeue_pi, which makes sense, because futex_wait_requeue_pi’s thread will be the waiter for the uaddrB futex. So this stack object must be dangling after futex_wait_requeue_pi returns.
Pinning down the bug
So, we now need to figure out what caused futex_wait_requeue_pi to return while the waiter it created is still in use. To do that, let’s set a breakpoint at the end of futex_wait_requeue_pi and step backwards.
As you can see, after this thread is awakened from futex_wait_queue_me, its q.rt_waiter is NULL, but before it went to sleep, it was defined as q.rt_waiter = &rt_waiter. This is, in fact, very bad — because q.rt_waiter is now NULL, futex_wait_requeue_pi thinks that its waiter has been already been cleaned up, so doesn’t bother to try itself and leaves the dangling rt_waiter in the wait_list.
1 | /* Here q->rt_waiter is NULL, so this branch is taken */ |
Finally, let’s figure out who set q.rt_waiter to NULL.
It’s the call to requeue_pi_wake_futex, which is called when the main thread’s second futex_requeue attempts to wake thread 2.
Reverse-stepping into the previous function, we can determine exactly why futex_requeue decides to wake thread 2. futex_lock_pi_atomic checks if the uaddrB futex is free with an atomic cmpxchg. If uaddrB is 0, then the cmpxchg succeeds and futex_lock_pi_atomic thinks it’s acquired the futex, so the main thread thinks it is time to wake up thread 2.
And of course, our PoC did exactly that — set uaddrB to 0 right before re-calling futex_requeue in step 4, hijacking the control flow of futex management.
Summary
To summarize, we used time-travel debugging under PANDA to record a kernel bug and explore it deterministically. We found that that mysterious uaddrB = 0 line caused all this trouble. By making futex_requeue think that uaddrB was free and had no more waiters, that line caused thread 2 to wake up in an inconsistent state. This led to a dangling rt_waiter on uaddrB's waitlist that eventually got corrupted, triggering a kernel panic.
You can take a look at the patch for this bug, which simply checks for a dangling waiter instead of blindly trusting the userspace uaddr value.
Future improvements
The above example demonstrated a powerful application of time-travel debugging, and more features should make it even more valuable. Support for ARM and PowerPC is on the horizon, and I’d like to reach command parity with Mozilla rr.
Performance
The most expensive part of time-travel in terms of space is checkpointing, aka making snapshots. Every checkpoint takes up as much memory as the guest VM has access to. It would be nice to add a delta-checkpoint mechanism to QEMU to apply smaller diffs between checkpoints, which could greatly reduce the space requirements.
The slowest part is the forward pass through every checkpoint, which could take a while depending on how widely spaced your checkpoints are. Also, if you give rsi a repeat count like rsi 20, GDB will naïvely run the rsi command 20 times, which involves 20 checkpoint restores. These perf issues should be addressed in future iterations.
While it’s still a work in progress and does have some instability, I invite you to try it out on your next full-system debugging task. Happy reversing!
References
https://appdome.github.io/2017/11/23/towelroot.html
https://github.com/SecWiki/linux-kernel-exploits/tree/master/2014/CVE-2014-3153